Can Current LAMs Play Super Mario?
Latent Action Models are starting to look surprisingly capable.
The basic promise is appealing: instead of requiring explicit action labels, a LAM watches how observations change over time and learns an action-like latent that can explain the transition. This has already led to encouraging results in controlled settings, and recent work even points toward cross-embodiment transfer, where action-like structure learned from one body or environment can remain useful in another.
But there is a quiet assumption hiding behind many of these successes: The setup is often clean, the agent is visually dominant, and the background is mostly stable. In other words, the model is placed in a world where the answer to “what caused this transition?” is almost visually obvious.
Now imagine teaching a LAM to play a video game.
Take a simple Mario clip. Mario is moving. A cloud is moving. The camera is scrolling to keep Mario near the center of the screen. A score digit increases in the background. Blocks, enemies, particles, and UI elements may all change at the same time. The screen is not just showing the agent’s action. It is showing a mixture of many transition sources.
From the model’s perspective, all of these changes arrive through the same channel: pixels at time $t$ and pixels at time $t + 1$. Unless we give the model stronger assumptions, it has no direct way to know which object is the agent of interest.
That is the core issue. What humans call a distractor may not be a distractor to the model. For an inverse dynamics model, the input is the full observation transition. For a forward dynamics model, the latent action must help predict the next observation. If background motion, camera motion, and non-agent objects are useful for prediction, then they can become part of the learned latent action interface.
This means the problem is not simply that video games are visually busy. The deeper problem is intrinsic ambiguity of agent without supervision.1
Don’t expect latent actions to encode the action you want
We suggest a different strategy.
Instead of forcing the LAM to decide which part of the transition belongs to the agent, we can postpone that decision. If a LAM cannot reliably know what the “agent of interest” is, then perhaps the first objective should not be agent identification. A more useful objective may be to build a clean and robust representation of what changed, under agent ambiguity.
To understand what such a representation should look like for a video game, we first need to accept a simple limitation: from two consecutive frames alone, we do not directly observe the true action.
An action is a cause. A frame transition is an effect.
By the time the LAM sees the transition, the original action has already been mixed with many other sources of change.
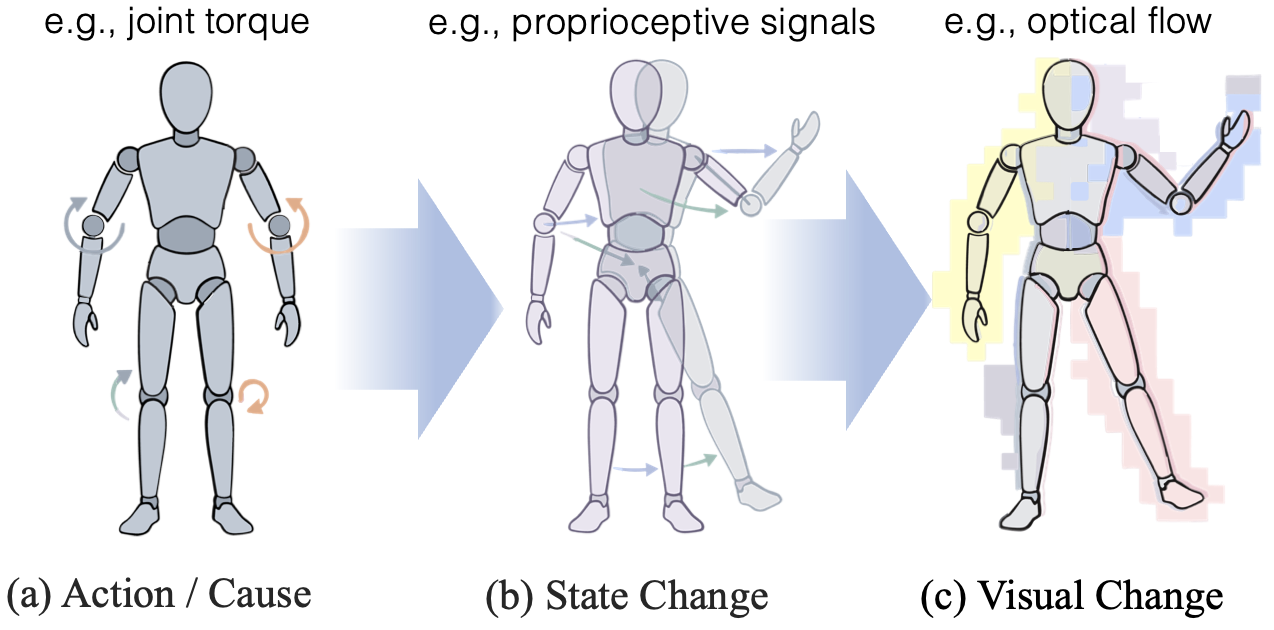
A useful way to think about this is as a three-stage chain.
- There are transition sources. Some are controlled, like the player’s action, while some others are uncontrolled.
- These sources produce a physical or game-state change.
- This state change becomes an observed visual effect in pixel space. Edges move. Textures shift. Objects appear or disappear. Local regions translate, deform, or flicker.
The LAM only receives the observed transition. Without extra supervision, it has no built-in reason to know which part should be called the action. So the question becomes less about recovering the true action immediately, and more about building the right intermediate representation.
Before we ask the model to decide what matters for control, we can ask it to describe the transition in a cleaner form. What moved? Where did it move? Which local visual effects appeared? Which parts of the frame changed together, and which changed independently?
This is a lower-level target than action, but it is also more honest. Under agent ambiguity, the most reliable thing we can extract from observation-only data is not necessarily the action itself, but the structure of the observed transition effect.
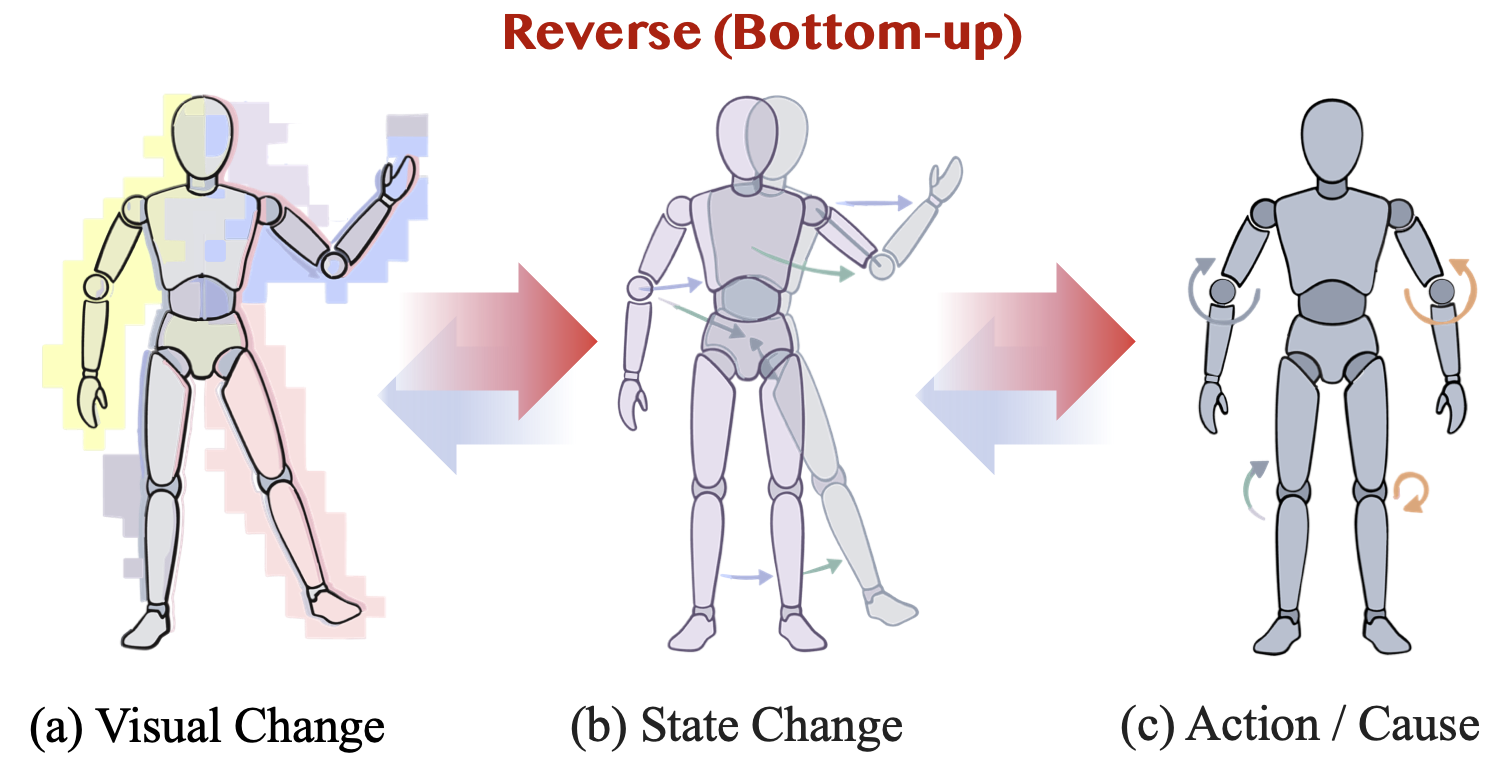
Bottom-up approach: building cause from noisy effects
We ultimately want a policy. The proposal is not to stop at observed effects, but to use them as a better starting point for control. In the 3-step action to transition setup, we use bottom-up strategy, from observed effects to latent action, and then from latent action to real action.
Bottom-up step 1: basic building blocks
To learn those building blocks, we use a VQ-VAE-style module called Observed Transition Factorization, or OTF.
The input and output of this module are both motion observations. Instead of reconstructing the next RGB frame directly, OTF is trained to reconstruct a motion-centered transition signal. The goal is to make the learned codebook focus on how the scene changes, rather than on what the scene looks like.
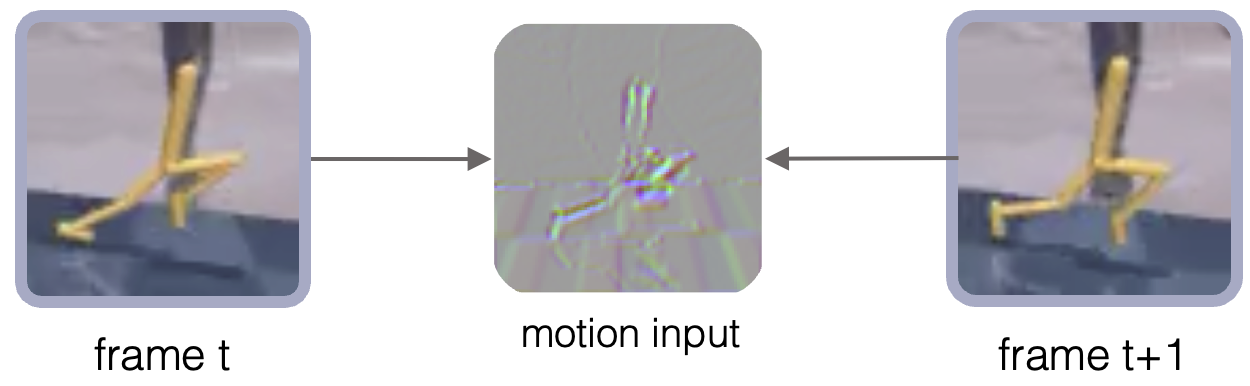
A useful motion primitive should be as environment-agnostic as possible. “Moving right” should mean roughly the same thing whether the carrier is Mario, Kirby, a robot arm, or a distractor object. The visual appearance may change, but the local transition effect can still be shared. For this reason, we do not simply concatenate $x_t$ and $x_{t+1}$ as input. Concatenation would leave too much room for the encoder to memorize appearance and environment-specific details. Instead, we construct a motion input by subtracting or transforming the two frames so that the remaining signal emphasizes change. This motion input has the same spatial shape as the original observation, but contains more direct information about the transition.
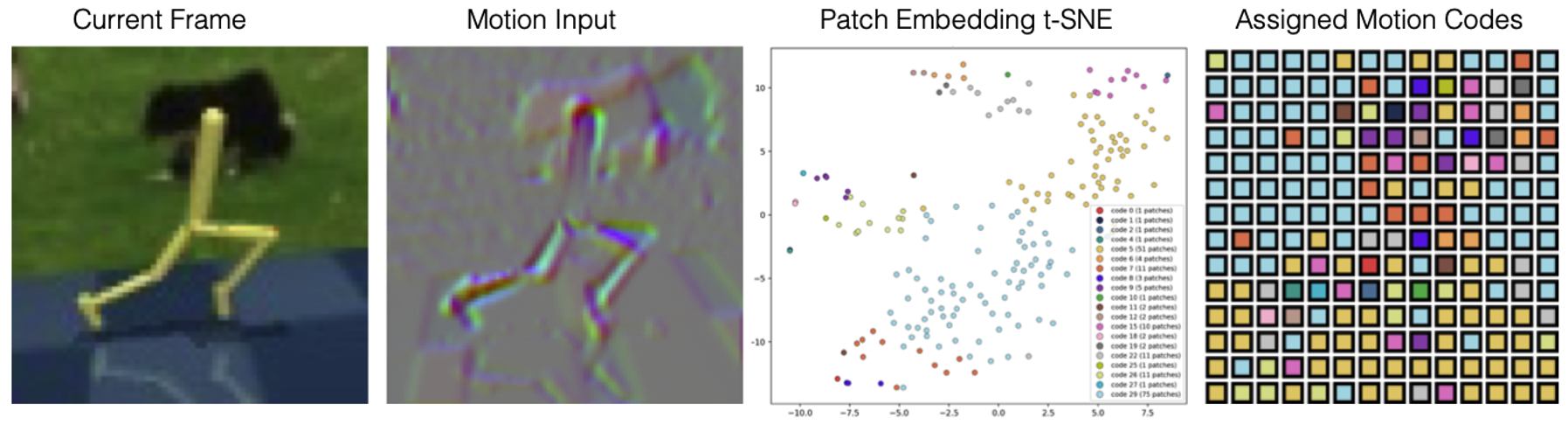
The motion input is then divided into small spatial patches. Each patch is encoded into a local transition embedding. During training, the model learns a fixed-size codebook, and each patch embedding is assigned to its nearest code. Each code can be interpreted as a reusable local motion primitive.
The decoder receives these quantized patch codes and reconstructs the motion observation. It also receives the current frame $x_t$ as a reference. $x_t$ provides appearance and spatial support, so the codebook does not need to store everything about the scene. It can focus more on the transition pattern itself.
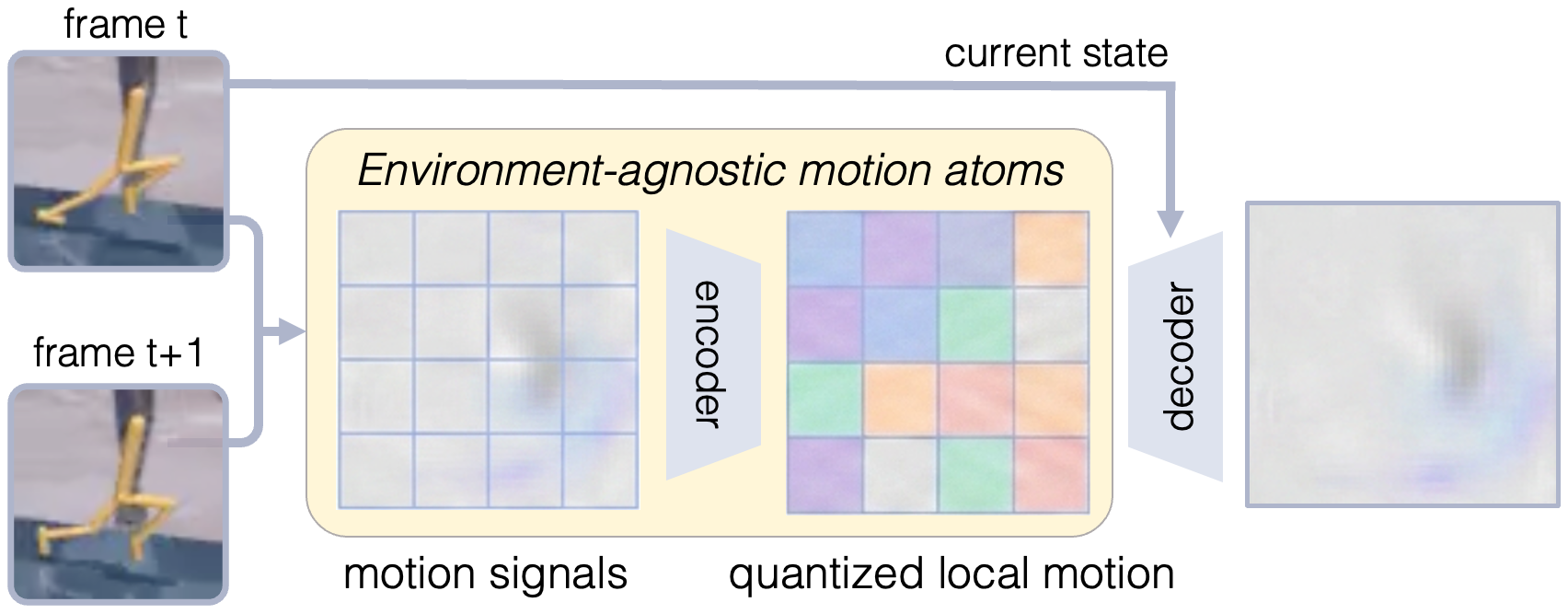
This structure gives the LAM a better starting point. Instead of compressing the whole transition into one monolithic latent action, OTF first exposes the transition as a set of local observed effects.
Bottom-up step 2: training the LAM on top of OTF
The LAM training stage then follows the conventional inverse-dynamics and forward-dynamics structure. The main difference is that the inverse side no longer compresses the raw frame transition directly into a single latent action. Instead, the frozen OTF module first extracts a set of motion primitives from the transition, and those primitives are then passed into an action aggregator.
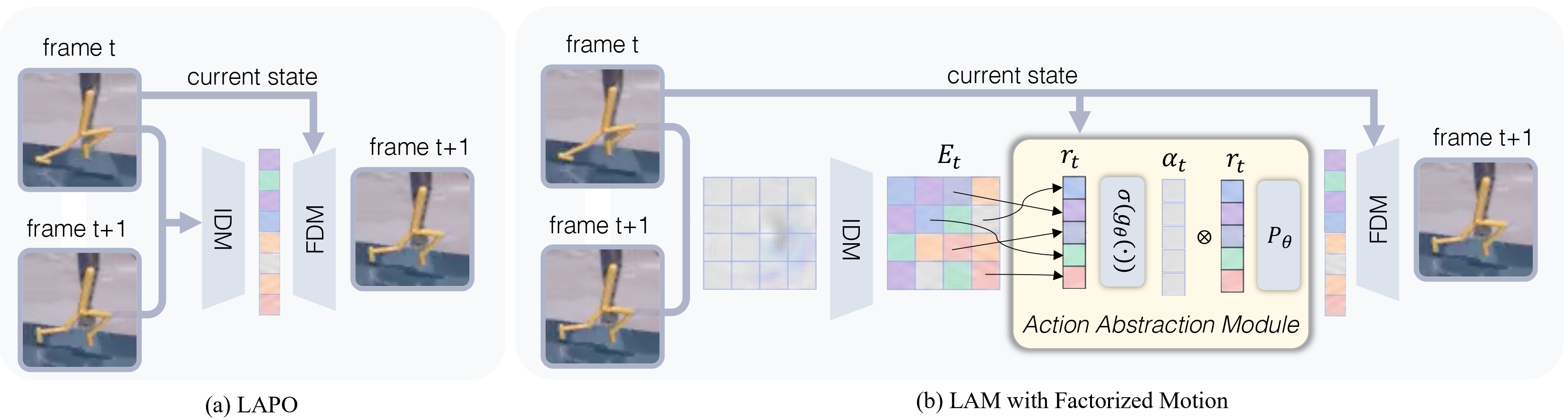
The aggregator is the module that turns this set of motion primitives into one compact latent action embedding. From this point on, the model looks much closer to a standard LAM: the latent action is used together with the current state to predict the next observation or next representation.
The aggregator is allowed to become environment-specific. This is necessary because action is not defined by motion alone. The same rightward motion can mean different things depending on the current state, object identity, and task context. For this reason, the aggregator also uses $x_t$. The current frame provides the state information needed to interpret the motion primitives.
Again, the goal of a LAM is to provide a useful representation for downstream policy learning. Instead of mapping two consecutive observations directly into a single monolithic embedding, this compositional structure keeps different sources of change separable long enough for the policy to learn which changes are truly action-relevant, without inheriting spurious correlations from the visual transition.
Bottom-up step 3: mapping latent changes to real actions
The final step is to connect the learned latent action space back to real actions.
The visual transition alone is not invertible back to the true action. Many different causes can produce similar observed effects, and many non-agent changes can appear in the same transition. But action supervision can resolve this inverse ambiguity.
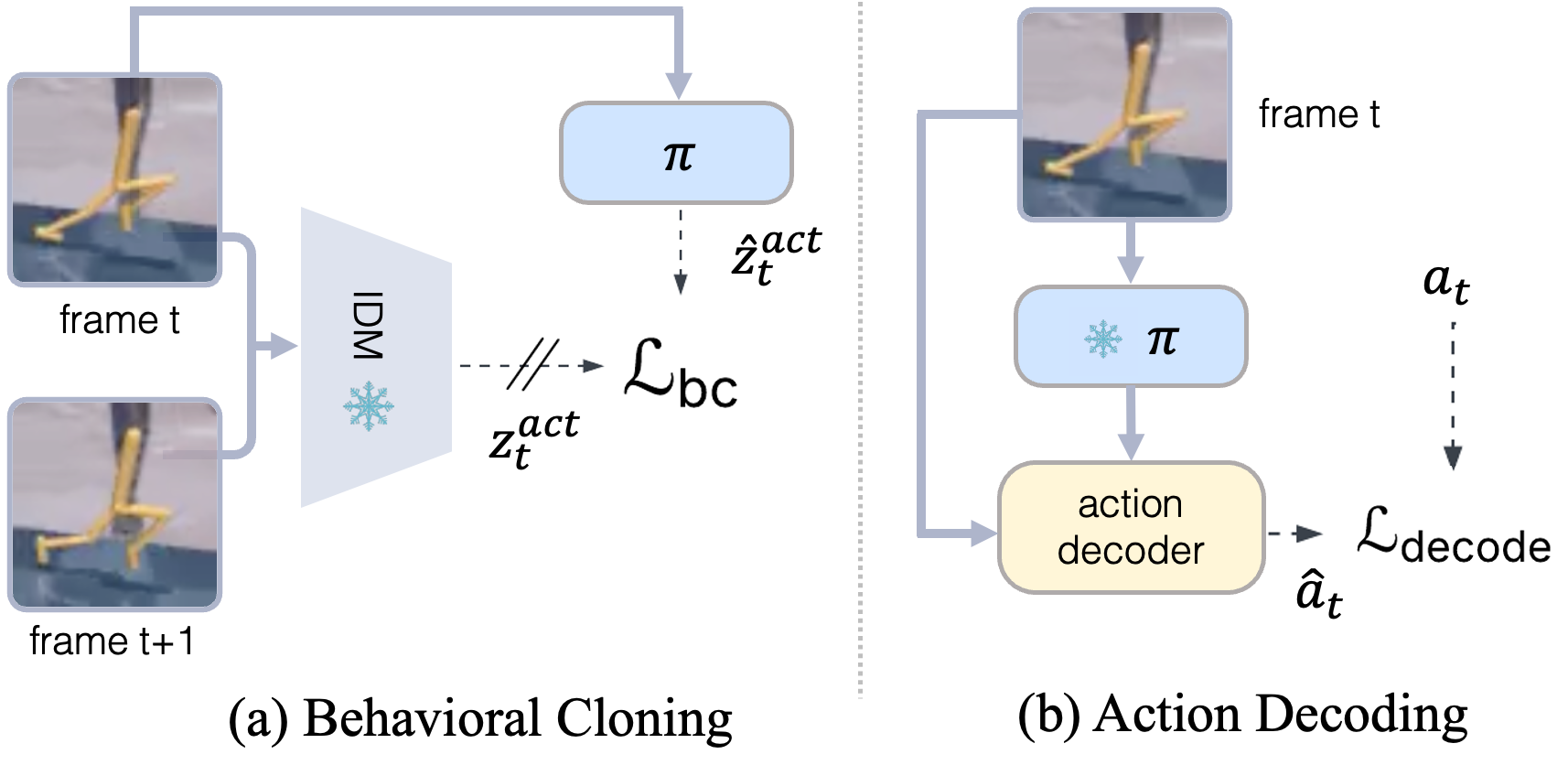
In this setup, we use the learned latent action space as the target for behavioral cloning. A policy is trained to predict the latent action embedding from the current observation. Then, using a small action-labeled dataset, we train an action decoder that maps the predicted latent action into the true action space.
This keeps the amount of action supervision small. Most of the structure is learned from observation-only transitions: first as reusable motion primitives, then as state-aware latent actions. The action labels are only used at the final stage, where they tell the model which explanation of the transition corresponds to the real controllable action.
OTF-LAM within DINO-WM?
There is one more natural extension: instead of predicting the next frame in pixel space, we can predict the next state in a frozen visual representation space.
This gives us OTF-LAM-DINO.
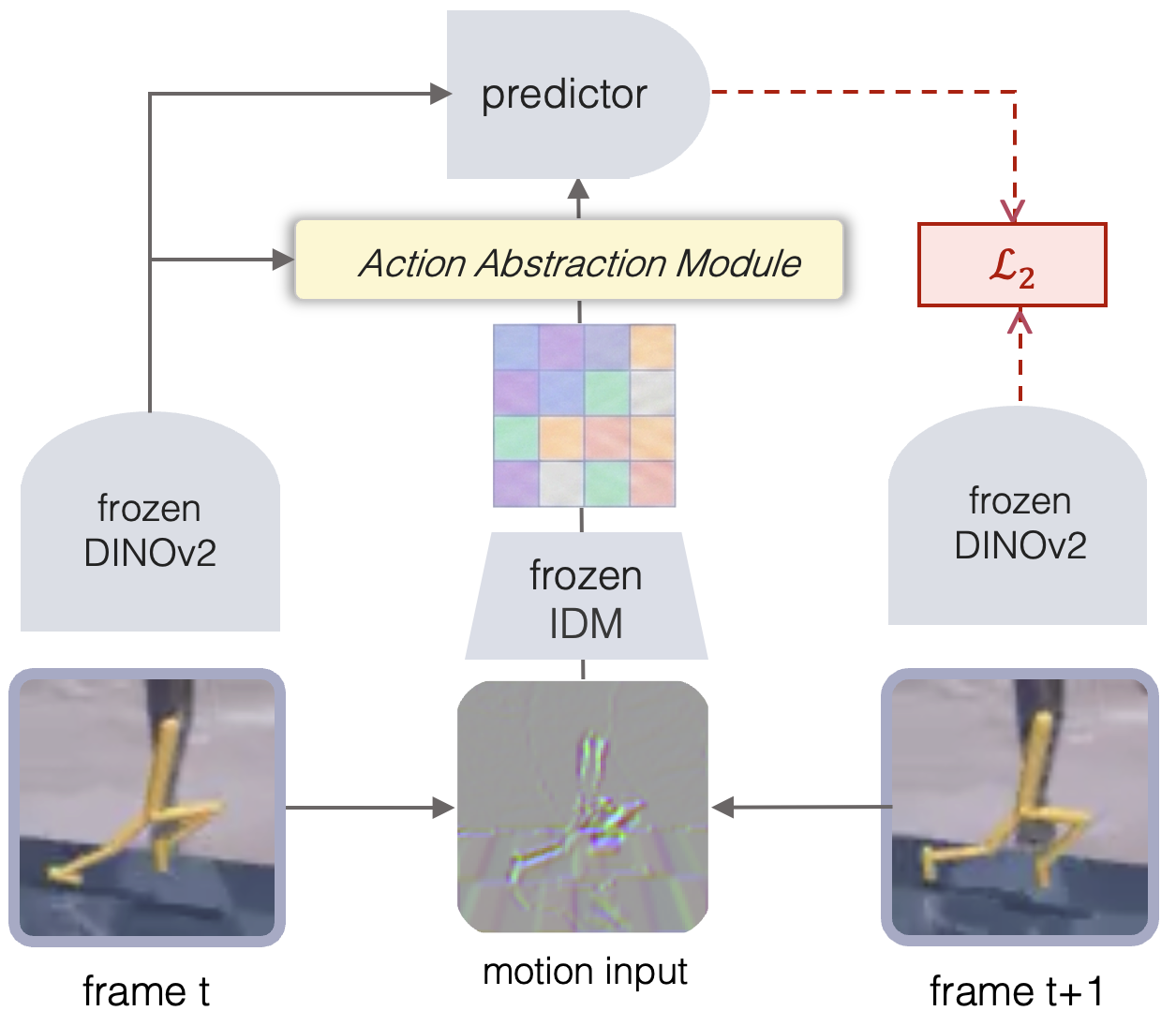
In this sense, OTF-LAM-DINO is close in spirit to DINO-WM. Both use frozen visual features as a more stable state space for dynamics learning. The difference is that OTF-LAM-DINO focuses on the action side: it asks how to build an action-like latent from observation-only transitions, while keeping both the visual state representation and the low-level transition vocabulary reusable.
This makes the separation sharper. OTF provides reusable observed-transition primitives. DINO provides a reusable visual state space. The remaining learned part is the environment-specific bridge between them: the aggregator and predictor that turn local transition effects into a state-aware latent action.
Results at a Glance
- OTF primitives transfer across visual carriers. Motion primitives learned from training data can be zero-shot transferred to unseen visual carriers, suggesting that the codebook captures reusable transition effects rather than digit-specific appearance.
- Monolithic latents can be brittle under shift of visual carrier.
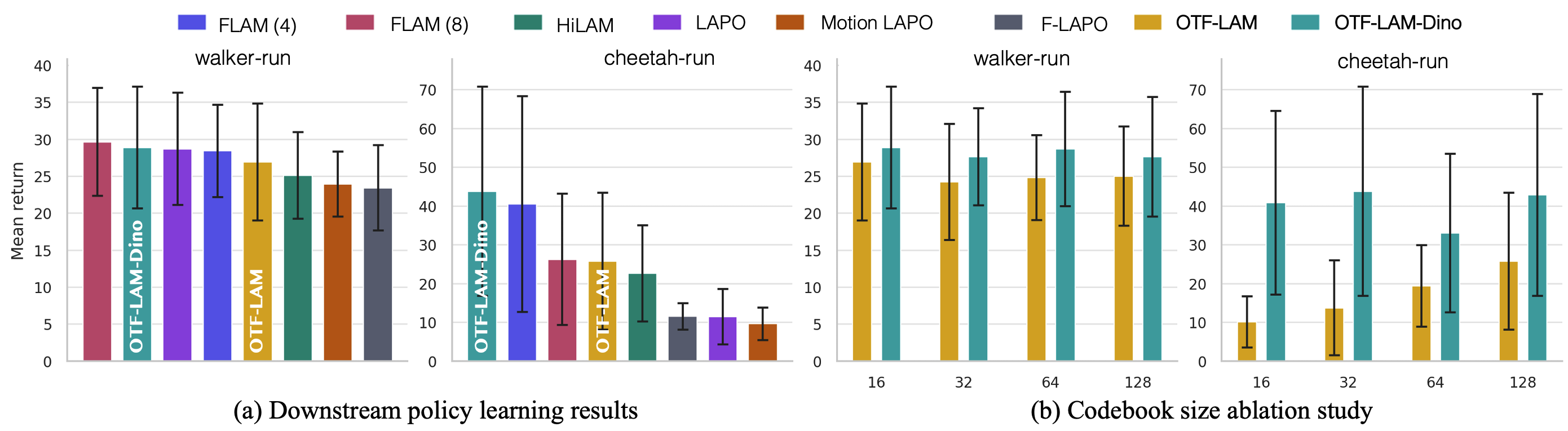
- OTF is competitive for downstream policy learning. It does not always beat every baseline in every fixed environment, but compatible to baselines or often better. FLAM is one of the strongest baselines, but it explicitly use object-centric learning to separate multiple sources of change.
- OTF-LAM-DINO improves the interface further. Predicting future DINOv2 features instead of pixels reduces pressure to model texture, lighting, and other pixel-level nuisance factors.
- Codebook size is a capacity trade-off. Larger vocabularies can help when motion is more complex, but more codes do not always mean better control performance.
Bibtex Citation
If you want to cite this work, please use the following BibTeX entry:
-
Inverse ambiguity is structural here, not just a nuisance variable issue. Two visually similar transitions can come from different causes, while a single action can look different depending on state, camera motion, and other entities on screen. ↩